 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
[혼공분석 4주차] 혼자공부하는 데이터 분석 with 파이썬
이번 주에는 pandas와 numpy에서 제공하는 메서드를 이용하여 편리하게 기술통계량(평균, 중앙값, 최솟값, 최대값, 분위수, 분산, 표준편차, 최빈값) 등을 계산하고 분석하는 방법에 대해서 살펴보았습니다. 이를 통해 따로 코딩으로 기술통계량을 작성할 필요 없이 제공되는 기능을 활용하여 원하는 통계 정보를 손쉽게 구할 수 있었습니다.
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
두 번째 챕터에서는 matplotlib 패키지를 활용하여 데이터의 분포와 특성을 시각적으로 요약하는 방법에 대해 배웠습니다. 이를 위해 hist() 메서드를 사용하여 산점도(scatter plot), 히스토그램(histogram), 상자 수염 그림(box-and-whisker plot) 등 다양한 그래프를 그려 데이터의 요약 정보를 한눈에 파악할 수 있습니다.
데이터의 분포를 시각화하는 가장 일반적인 방법 중 하나는 산점도(Scatter Plot)입니다. 산점도는 두 변수 간의 관계를 나타내는 그래프로, 데이터 포인트를 점으로 표현하여 x축과 y축에 대응하는 값을 비교합니다. 이를 통해 변수 간의 상관 관계나 패턴을 파악할 수 있습니다.
또한, 히스토그램(Histogram)은 데이터의 분포를 나타내는 그래프입니다. 주어진 데이터를 구간으로 나누고 각 구간에 속하는 데이터의 개수를 세어 막대 그래프로 표현합니다. 이를 통해 데이터의 분포 모양과 중심 경향을 파악할 수 있습니다.
또 다른 방법으로는 상자 수염 그림(Box Plot)을 사용할 수 있습니다. 상자 수염 그림은 데이터의 최솟값, 최댓값, 중앙값, 사분위수 등을 시각적으로 표현하는 그래프입니다. 이를 통해 데이터의 중심 경향과 퍼짐 정도, 이상치 여부 등을 파악할 수 있습니다.
matplotlib 패키지를 사용하면 이러한 그래프들을 손쉽게 그릴 수 있습니다. 데이터의 특성과 분포를 시각적으로 파악함으로써, 데이터 간의 관계와 패턴을 이해하고 추가적인 분석과 결정에 도움이 됩니다.
- 기본미션 : p. 279의 확인 문제 5번 풀고 인증하기
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
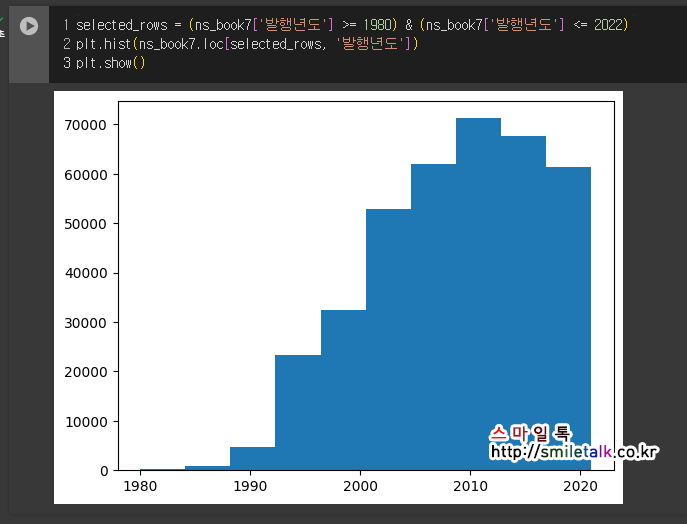
정답 :
selected_rows = (ns_book7['발행년도'] >= 1980) & (ns_book7['발행년도'] <= 2022)
plt.hist(ns_book7.loc[selected_rows, '발행년도'])
plt.show()
- 선택미션 : Ch.04(04-1)에서 배운 8가지 기술통계량(평균, 중앙값, 최솟값, 최대값, 분위수, 분산, 표준편차, 최빈값)의 개념을 정리하기
- 평균(average)은 숫자 값을 모두 더해 개수로 나눈 값이다.
x = [10, 20, 30]
sum = 0
for i in range(3):
sum += x[i]
print("평균:", sum / len(x))
- 중앙값(median)은 전체 데이터를 순서대로 늘어 놓았을 때 중앙에 위치한 값을 말한다.
ns_book7['대출건수'].median()- 최솟값(min)은 전체 데이터에서 가장 값이 작은 수를 말한다.
ns_book7['대출건수'].min()- 최대값(max)은 전체 데이터에서 가장 값이 큰 수를 말한다.
ns_book7['대출건수'].max()- 분위수는 순서대로 나열된 데이터를 일정한 간격으로 나누는 기준입니다.
예를 들어 사분위 수는 데이터를 4등분하여 25%, 50%, 75%에 위치한 값입니다.
ns_book7['대출건수'].quantile([0.25, 0.5, 0.75])- 분산은 데이터의 퍼짐 정도를 나타내는 지표로, 각 데이터가 평균값으로부터 얼마나 떨어져 있는지의 제곱을 평균한 값입니다.
np.var(ns_book7['대출건수'])- 표준편차는 데이터의 분산 정도를 나타내는 지표로, 평균값으로부터 얼마나 떨어져 있는지를 나타냅니다. 즉, 데이터가 얼마나 퍼져 있는지를 알려주는 값이라고 할 수 있습니다.
np.std(ns_book7['대출건수'])- 최빈값은 주어진 데이터 집합에서 가장 자주 등장하는 값으로, 가장 빈도가 높은 값을 의미합니다.
values, counts = np.unique(ns_book7['도서명'], return_counts=True)
max_idx = values[np.argmax(counts)]
max_idx
#혼공학습단 #혼공 #혼공분석





{kind=link}
0 댓글