 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
[혼공분석 2주차] 혼자공부하는 데이터 분석 with 파이썬
이번주에는 내외부 데이터를 가져다 사용할수 있는 API 방법과 웹스크래핑(윀크롤링) 방법에 대해서 학습했으며, 데이터를 전달하는 JSON, XML 형식에 대해서도 알아보고 도서관 정보나루(https://www.data4library.kr/) 사이트에서 API 인증키를 발급 받아 '20대가 가장 좋아하는 도서' 정보를 추출해 보았으며,
아름다운 수프(Beautful Soup)를 활용해 Yes24 홈페이지에서 도서정보에 대한 웹스크래핑 실습도 해보았습니다.
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
- JSON, XML, API 사용법 정리
import json
json_str = {"name": "혼자 공부하는 데이터 분석", "author": "박해선", "year": 2022}
d_str = json.dumps(json_str, eensure_ascii=False)
print(d_str)
json.dumps() 함수를 사용하여 파이썬 객체를 JSON 형식에 맞는 텍스트로 바꿀수 있으며,
json.loads() 함수를 사용하여 반대로 JSON 문자열을 파이썬 객체로 변환할수 있습니다.
import xml.etree.cElementTree as et
books = et.fromstring(x2_str)
for book in books.findall('book'):
print(book.findtext('name'))
xml.etree.ElementTree 모듈을 사용하여 fromstring() 함수로 문자열을 XML 형식으로 변환할수 있습니다.
import requests
url = "http://www.api.com/api"
r = requests.get(url)
data = r.json()
print(data)
requests 패키지를 사용하여 API 데이터를 불러올수 올수 있고, json() 메서드를 사용하여 JSON문자열을 파이썬 객체로 변환할수 있습니다.
- 기본미션 : p. 150의 확인 문제 1번 풀고 인증하기
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
import pandas as pd
df_data = {'col1':['a','b','c'], 'col2':[1,2, 3]}
df = pd.DataFrame(df_data)
print('============ 1 번 ============')
df.loc[[0,1,2],['col1','col2']]
print('============ 2 번 ============')
df.loc[0:2, 'col1':'col2']
print('============ 3 번 ============')
df.loc[:2, [True, True]]
print('============ 4 번 ============')
df.loc[::2, 'col1':'col2']
정답 : 4번
4번에 '::2'는 2행씩 건너뛰어 선택하라는 의미 입니다.
- 선택미션 : p137 ~ 138 손코딩 실습으로 원하는 도서의 페이지 수를 추출하고 화면 캡쳐하기
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
def get_page_cnt(isbn):
url = 'https://www.hanbit.co.kr/search/search_list.html?keyword={}'
r = requests.get(url.format(isbn))
soup = BeautifulSoup(r.text, 'html.parser')
prd_info = soup.find('a', attrs={'class':'gd_name'})
if prd_info == None:
return ''
url = 'https://www.hanbit.co.kr' + prd_info['href']
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
prd_detail = soup.find('div', attrs={'id':'infoset_specific'})
prd_tr_list = prd_detail.find_all('tr')
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
return tr.find('td').get_text().split()[0]
return ''
get_page_cnt(9791169210287)
지금 학습하고 있는 '혼자 공부하는 데이터 분석 with 파이썬' 교재의 ISBN '9791169210287' 으로 검색해 봤습니다.
- API 활용한 응용
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
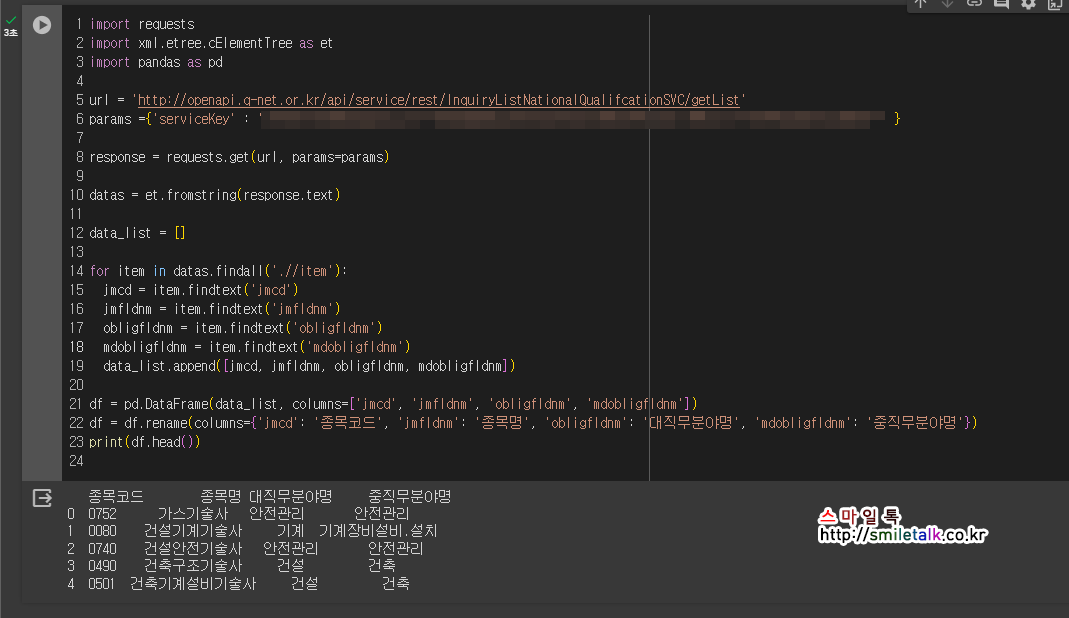
import requests
import xml.etree.cElementTree as et
import pandas as pd
url = 'http://openapi.q-net.or.kr/api/service/rest/InquiryListNationalQualifcationSVC/getList'
params ={'serviceKey' : '서비스키' }
response = requests.get(url, params=params)
datas = et.fromstring(response.text)
data_list = []
for item in datas.findall('.//item'):
jmcd = item.findtext('jmcd')
jmfldnm = item.findtext('jmfldnm')
obligfldnm = item.findtext('obligfldnm')
mdobligfldnm = item.findtext('mdobligfldnm')
data_list.append([jmcd, jmfldnm, obligfldnm, mdobligfldnm])
df = pd.DataFrame(data_list, columns=['jmcd', 'jmfldnm', 'obligfldnm', 'mdobligfldnm'])
df = df.rename(columns={'jmcd': '종목코드', 'jmfldnm': '종목명', 'obligfldnm': '대직무분야명', 'mdobligfldnm': '중직무분야명'})
print(df.head())
공공데이터포털(https://www.data.go.kr/index.do) 사이트에서 '한국산업인력공단 국가자격 종목 목록 정보' API를 활용하여 이번주에 학습한 방법을 활용하여 XML값으로 불러온 데이터 중에서 원하는 값들만 추출해서 데이터프레임으로 국가자격증에 대해서 종목코드, 종목명, 대직무분야명, 중직무분야명에 대해서 최근 5개만 출력하는 코드를 작성해 봤습니다.
이번주 학습한 것들을 잘 활용하면 다양하게 사용할수 있을듯 합니다.
#혼공학습단 #혼공 #혼공분석






{kind=link}
0 댓글