 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
[혼공분석 1주차] 혼자공부하는 데이터 분석 with 파이썬
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
이번주는 '혼자공부하는 데이터 분석 with 파이썬' 교재를 가지고 혼공온라인스터디를 시작하는 첫번째 주로써, 데이터 분석이란 무엇이고, 데이터분석에 주로 사용하는 파이썬과 R 프로그램에 대한 비교와 파이썬에서 필수적으로 사용하는 패키지인 넘파이(NumPy), 판다스(pandas), 맷플롯립(matplotlib), 사이파이(SciPy) 그리고 사이킷런(scikit-learn)에 대해서 간단하게 알아 보았으며,
실습을 위한 학습 환경으로 쥬피터 노트북(Jupyter notebook)을 설치하거나 구글 코랩(Colab) 중에 사용을 해야 하는데, 쥬피터 노트북은 여러 장점이 있기는 하지만, 설치하는데 용량도 적지 않으며, 파이썬 프로그램과 필요한 패키지 등을 따로 설치를 해야 하지만, 구글 코랩은 온라인으로 브라우저를 이용해서 접속을 통해서 실습을 할수 있기 때문에, 구글에서 제공하는 서버의 자원을 사용하여 온라인으로 접속할수 있는 환경이라면 어디서든 제한 없이 이용할수 있어 몇가지 단점이 있기는 하지만, 장점이 더 많아서 교재에서도 그렇고 저도 구글 코랩을 이용해서 실습을 했습니다.
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
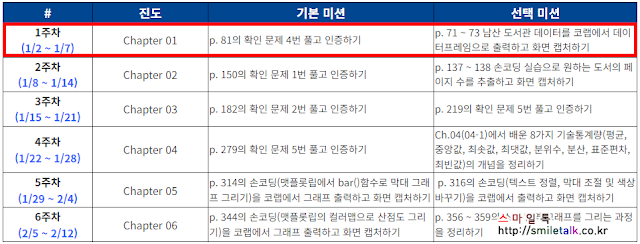
- 기본미션 : p. 81의 확인 문제 4번 풀고 인증하기
정답 : 3번
https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
pandas API reference 사이트에서 참고하면,
header의 default parameter는 'infer' 이며, names의 parameter에는 'Sequence of column labels to apply.' 열 이고, dtype의 parameter에는 'Data type(s) to apply to either the whole dataset or individual columns' 모든 열의 데이터 타입을 지정을 해도 되고 안해도 됩니다.
read_csv() 함수에 대해서 추가로 정리를 해보자면,
read_csv() 함수는 데이터를 CSV(Comma-Separated Values) 파일로부터 읽어오는 함수입니다. CSV 파일은 각 열을 쉼표로 구분하여 데이터를 저장하는 텍스트 파일 형식입니다. read_csv() 함수는 주로 데이터 분석 및 처리에 사용되는 판다스(Pandas) 라이브러리에서 제공되는 함수입니다.
read_csv() 함수는 다양한 매개변수를 사용하여 데이터를 읽어올 수 있습니다. 주요 매개변수에는 다음과 같은 것들이 있습니다:
- filepath (필수): 읽어올 CSV 파일의 경로를 지정합니다.
- sep (선택적): CSV 파일에서 열을 구분하는 구분자(delimiter)를 지정합니다. 기본값은 쉼표(,)입니다.
- header (선택적): CSV 파일의 첫 번째 행을 열 이름으로 사용할지 여부를 지정합니다. 기본값은 첫 번째 행을 열 이름으로 사용합니다.
- index_col (선택적): 지정된 열을 인덱스로 사용할지 여부를 지정합니다. 기본값은 인덱스를 사용하지 않습니다.
- usecols (선택적): 읽어올 열의 인덱스나 열 이름을 지정하여 특정 열만 읽어올 수 있습니다.
- dtype (선택적): 열의 데이터 타입을 지정할 수 있습니다.
read_csv() 함수를 호출하면 CSV 파일의 내용이 데이터 프레임(DataFrame) 형태로 반환됩니다. 데이터 프레임은 판다스에서 제공하는 테이블 형태의 데이터 구조입니다. 이를 통해 데이터를 쉽게 조작하고 처리할 수 있습니다.
아래는 read_csv() 함수의 간단한 예제입니다:
import pandas as pd
# CSV 파일 읽기
data = pd.read_csv('파일경로.csv')
# 데이터 확인
print(data.head())
위의 예제에서 read_csv() 함수는 '파일경로.csv' 파일을 읽어와 데이터 프레임으로 저장합니다. 그리고 head() 함수를 사용하여 데이터의 일부를 출력합니다.
read_csv() 함수는 데이터 분석 및 처리를 위해 매우 유용한 함수입니다. 데이터 프레임을 통해 데이터를 쉽게 조작하고 필요한 작업을 수행할 수 있습니다.
- 선택미션 : p. 71 ~ 73 남산 도서관 데이터를 코랩에서 데이터프레임으로 출력하고 화면 캡쳐하기
 |
| @[혼공스터디] 혼자공부하는 데이터분석 with 파이썬 |
import pandas as pd
df = pd.read_csv('남산도서관 장서 대출목록 (2023년 12월).csv', encoding='EUC-KR', low_memory=False)
df.head()교재는 2021년 4월 남산도서관 장서 대출목록을 사용했는데, 저는 최근인 2023년 12월 남산도서관 장서 대출목록을 사용해서 실습을 했습니다.
#혼공학습단 #혼공 #혼공분석






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
0 댓글